Quicksort is similar to Mergesort in that the sort is accomplished by dividing the array into two partitions and then sorting each partition recursively. However, in quicksort, the array is partitioned by placing all items smaller than some pivot item before that item and all items larger than the pivot item after it. The pivot item can be any item, and for convenience we will simply make it the first one.
퀵정렬은 선택된 피벗값을 기준으로 배열을 두 개의 파티션으로 나누고 재귀를 이용하여 각 파티션을 정렬한다는 점에서 합병정렬과 비슷하나, 정렬과정에서 추가적인 작업공간을 필요로 하지 않는다. 즉, 퀵정렬은 in-place sort이다.
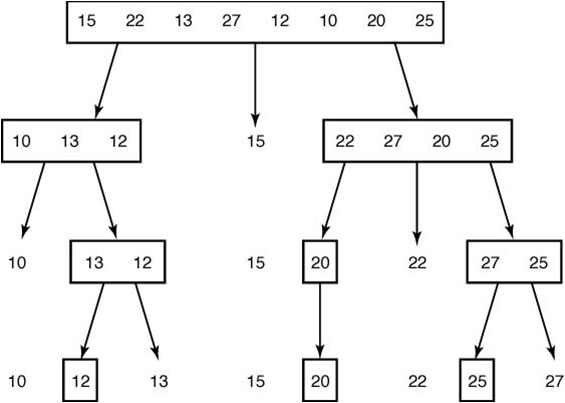
Example The steps done by a human when sorting with Quicksort.
Quicksort Algorithm
Algorithm Design
Partition the array so that all items smaller than the pivot item are to the left of it and all items larger are to the right.
Sort the subarrays.
선택된 피벗 값을 기준으로 피벗보다 작은 값들은 왼쪽에, 큰 값들은 오른쪽에 오도록 배열을 분할하고 각 부분배열을 정렬한다.
Pseudo Code
voidquicksort(index low, index high) { index pivotpoint;
voidpartition(index low, index high, index& pivotpoint) { index i, j; keytype pivotitem;
pivotitem = S[low]; // Choose first item for pivotitem. j = low; for (i = low+1; i <= high; i++) if (S[i] < pivotitem) { j++; exchange S[i] and S[j]; } pivotpoint = j; exchange S[low] and S[pivotpoint]; // Put pivotitem at pivotpoint. }
namespace algorithms { voidquicksort(int data[ ], int low, int high); // Problem: Sort n keys in nondecreasing order. // Inputs: positive integer n, array of keys S indexed from 1 to n. // Outputs: the array S containing the keys in nondecreasing order.
voidpartition(int data[ ], int low, int high, int& pivotpoint); // Problem: Partition the array S for Quicksort. // Inputs: two indices, low and high, and the subarray of S indexed // from low to high. // Outputs: pivotpoint, the pivot point for the subarray indexed // from low to high. }
namespace algorithms { voidquicksort(int data[ ], int low, int high) { int pivotpoint;
if (high > low) { partition(data, low, high, pivotpoint); quicksort(data, low, pivotpoint-1); // before the pivotpoint quicksort(data, pivotpoint+1, high); // after the pivotpoint } }
voidpartition(int data[ ], int low, int high, int& pivotpoint) { int i, j; int pivotitem;
pivotitem = data[low]; // Choose first item for pivotitem. j = low; for (i = low+1; i <= high; ++i) { if (data[i] < pivotitem) { ++j; std::swap(data[i], data[j]); } } pivotpoint = j; std::swap(data[low], data[pivotpoint]); // Put pivotitem at pivotpoint. } }
// PROTOTYPE of a function that will test one of the sorting functions: voidtestsort(void sorter(int data[ ], int start, int last), constchar* file_name, constchar* sorting_name);
voidopen_for_read(ifstream& f, constchar filename[ ]); // Postcondition: The ifstream f has been opened for reading using the given // filename. If any errors occurred then an error message has been printed // and the program has been halted.
boolis_more(istream& source); // Precondition: input is an open istream. // Postcondition: The return value is true if input still has more data to // read; otherwise the return value is false.
voidprocess_read(ifstream& f, int data[ ]); // Precondition: input is an open istream. // Postcondition: The values in inputfile are assigned to data array.